
Bioinformatics Automations Solutions on AWS
Bioinformatics analysis is complicated. There is no one size fits all solution, and most infrastructures are created from many different components.
Get Started
Data Visualization
Deploy load balanced, fault tolerant RShiny and Dash applications on AWS. Each deployment is completely customizable and can include additional file systems, databases, and compute clusters.

SLURM HPC Clusters
Explore your large datasets on your own HPC Cluster on AWS. Avoid having to manually bring instances up and down with on demand by leveraging the scheduler to do the work for you.
Data Science Pipelines
Design complex data science pipelines with the help of Apache Airflow. Generate QC reports, label images, train models, and execute computationally intensive workloads with the help of AWSBatch or HPC.
Icons from www.flaticon.com
Free
DIY
less than $100 USD
Paid 1 hour Road-mapping and Strategy Session
$300 USD
Data Science Infrastructure and Clusters
Starts at $5K USD
Retainers for Longer-Term Projects
Minimum of $3K per month for a minimum of 3 months
Bioinformatics Analysis Optimization with Apache Airflow
Starts at $5K USD
Here's a Preview
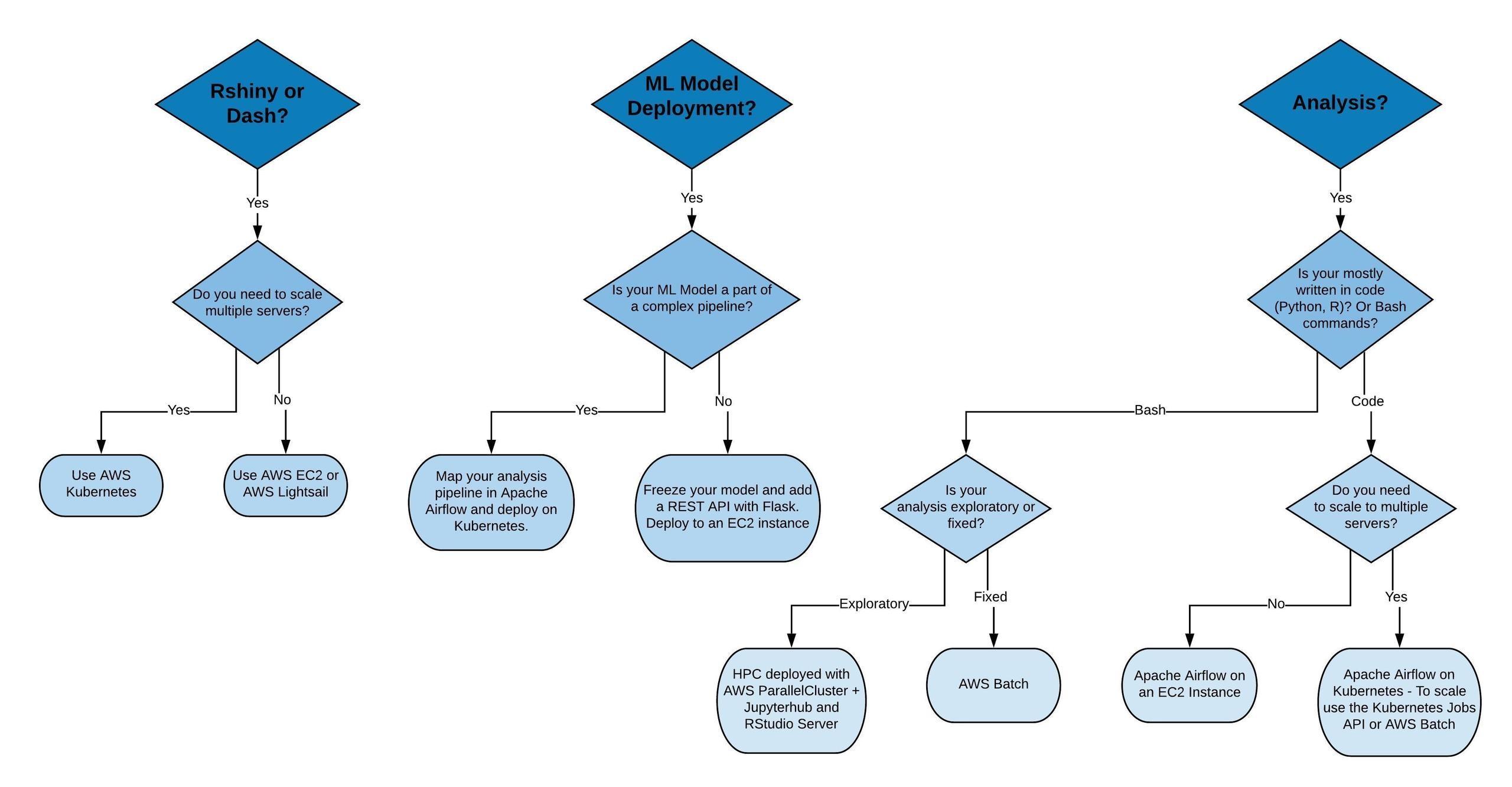
Bioinformatics analyses always share common traits. These traits will point you towards the type of infrastructure you need to automate and scale your analyses or exploratory data science infrastructure.
Why Work With Me?
Over the course of my career, I have earned a robust reputation for outstanding genomics and bioinformatics DevOps, and I am known for my ability to design and integrate innovative, flexible infrastructures, leveraging in-depth client and business consultation to uncover critical, unique program needs. Throughout the years I’ve seen datasets grow in size and complexity (who remembers microarrays?) and worked with researchers to develop analysis infrastructure to accommodate the ever-growing demand for more number crunching.
I have consulted with the Bioinformatics Contract Research Organization (CRO) and BitBio to design and deploy a major manual-labor saving HPC cluster with integrated SLURM scheduler and user / software stacks, and elastic computational infrastructure for genomics analysis, empowering a greater focus on high-priority projects and activities.
I also designed and deployed complex data visualization applications on AWS such as NASQAR. I am both a contributor and core team member of Bioconda as well as a contributor to the Conda Ecosystem and EasyBuild.
Let's Deploy!
Prefer to DIY?
That's great! I have oodles of material for people who want to deploy their own resources.
Deploy all the things!
Here are some blog posts that I hope find helpful! If you have any requests for tutorials please don't hesitate to reach out to me at [email protected].
Data Science and Machine Learning Pipelines
-
Setup a High Content Screening Imaging Platform with Label Studio
- Get Started with CellProfiler in Batch
Data Visualization Applications AWS

